7Several variables
A function of several variables usually refers to a function where is a natural number. We have already seen functions of several variables with . In particular, in Chapter 4, we saw linear functions (in connection with linear programming) like This is a rather simple function of several variables with in (7.1). In general functions as in (7.1) can be wildly complicated. One of the main purposes of this chapter is to zero in on the class of differentiable functions in (7.1). In Chapter 6 we defined what it means for a function of one variable to be differentiable. This was inspired by a drawing of the graph of the function. In several variables (for ) one has to be a bit clever in the definition of differentiability. The upshot is that the derivative at a point now is a row vector (or more generally a matrix) instead of being a single number. As an example, using notation that we introduce in this chapter, the derivative of the function in (7.2) at is This notation means that partial differentiation with respect to a variable occurs i.e., one fixes the variable and computes the derivative with respect to this variable viewing all the other variables as constants.First some treasured memories from the author's past.7.1 Introduction
Many years ago (1986-89), I had a job as a financial analyst in a bank working (often late at night) with a spectacular view of Copenhagen from the office circled below.
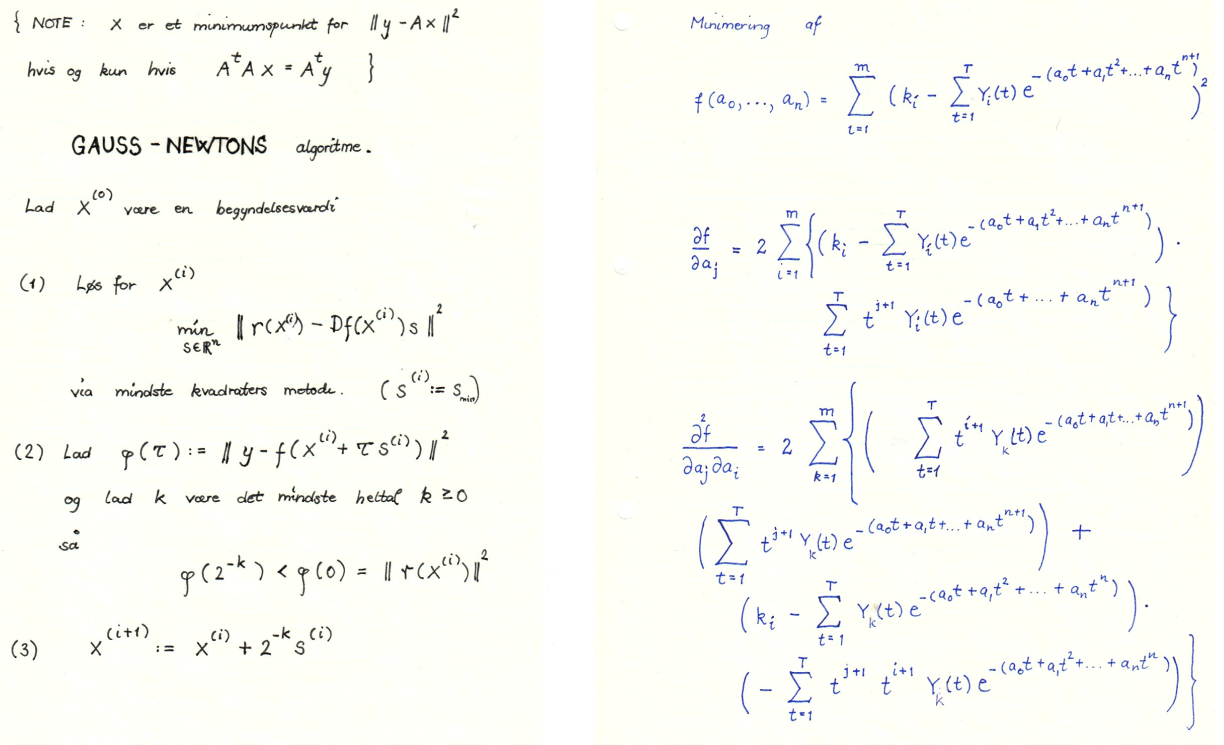

Illustrate the gradient descent method for . Pay attention to
the learning rate . How big is allowed to be, when
is required and ?
This is a hands-on exercise: carry out the gradient descent method
numerically for the function
to solve the minimization problem
starting with .Hint
Recall the definition of a function being
differentiable at a point with derivative . Here we measured
the change of in terms of the change (in ). It had to have
the form
where is a function
continuous in with and small.
If you divide both sides of (7.3) by you recover
the usual more geometric definition of differentiability as
a limiting slope:
We wish to define differentiability at for a function
. In this setting the quotient
in (7.4) does not make any sense. There is no way we can divide
a vector by a vector , unless
of course as in (7.4), where we faced
usual numbers.The natural thing here is to generalize the definition in (7.3).
First let us recall what functions look like.
It is not clear how to choose the step size here. Proceed by letting be the
smallest natural number, such that
Stop the process, when .Helpful code
Is a convex function?Explain how the Newton-Raphson methodThis is an iterative method for approximating a zero for a differentiable function . It works by guessing and then iterating to get a sequence approximating a zero (). may be used to solve the minimization problem and
compute the minimum also using this method.Helpful code7.2 Vector functions
A function takes a vector as input and gives a vector as output. This means that every coordinate in the output must be a function of i.e., for . So in total, we may write as Each of the (coordinate) functions are functions from to .
Look back at Exercise 1.82. Write down precisely the
vector function occuring there.
The function is rotating
a vector degress counter clockwise. What are
and in
Hint
Try rotating some specific vectors like degrees.
Do you see a pattern?
7.3 Differentiability
The definition of differentiability for a function mimics (7.3), except that is replaced by . Also the open interval is replaced by an open subset and the (open) interval is replaced by an open subset containing . Notice, however, that now the derivate is a matrix!
Let be a
function with an open subset. Then is
differentiable at if there exists
- an matrix ,
- an open subset with , such that for every ,
- a function continuous at with ,
7.3.1 Partial derivatives
A function of one variable has a derivative with respect to . For a function of several variables we have a well defined derivative with respect to each of these variables. These are called the partial derivatives (if they exist) and they are defined below.
Let be a function, where is an open subset
of . Fix a point and let
for . If is differentiable at according to Definition 7.3, then
we say that the partial derivative
of with respect to exists at and use the notation
The partial derivative with respect to a specific variable is computed by
letting all the other variables appear as constants.
Consider the function given by
Then
where . This example illustrates that
can be computed just like in the
one variable case, when the other variables () are treated
as constants. Notice that
Partial derivatives behave almost like the usual derivatives of one
variable functions. You simply fix one variable that you
consider the "real" variable and treat the other variables as constants.
Use the Sage window above to verify the computation of the partial
derivative in Example 7.9.
The following result tells us how to compute the matrix derivative.
Let be a function with an
open subset. If is differentiable at , then the
partial derivatives
exist for and and the matrix
in Definition 7.5 is
The -th column in is . Putting for
in Definition 7.5 gives
The -th coordinate of this identity of -dimensional vectors
can be written
where
and (7.6) shows that .
Compute the matrix derivative of the vector function in Exercise 7.4.
For a function with
an open subset, the partial derivative, if it exists for every , is a new function
We will use the notation
for the iterated (second order) partial derivative.The first part of following result is a converse to
Proposition 7.11. The second part contains the surprising
symmetry of the second order partial derivatives under rather mild
conditions. We will not go into the proof of this result, which is known as
Clairaut's theorem.
Let be a function with an
open subset. If the partial derivatives for exist at every with
continuous (for and ), then
is differentiable. If the second order partial
derivatives exist for a function
and are continuous functions,
then
for .
Verify (by hand!) the symmetry of the second order partial derivatives for the function
in Example 7.9 i.e., show that
Verify that given by
is a differentiable function by computing
and applying Theorem 7.13. Check also that
7.4 Newton-Raphson in several variables!
There is a beautiful generalization of the Newton-Raphson method to several variable functions . Consider first that you would like to solve the system of non-linear equations in the two variables and . Notice that we are talking non-linear here. This is so much more difficult than the systems of linear equations that you encountered in a previous chapter.However, just like we used Newton's method in one variable for solving a non-linear equation, Newton's method for finding a zero for a function generalized to the iterative scheme
Verify the claim in (7.10) by applying (7.8) to
Carry out sufficiently many iterations starting with the vector in
(7.10) to see the iteration stabilize. You should do this
using a computer, for example by modifying the Sage code in the last half of Example 7.18.
7.5 Local extrema in several variables
For a function , where , the derivative at is called the gradient for at . Classically, it is denoted i.e., The definition below is stolen from the one variable case.
Let be a function, where is
an open subset. Suppose that the partial derivatives exist at
. Then is called a critical
point for if .
Consider the function given by
corresponding to finding critical points for the function
You can left click and hold the graph computed below (after it has rendered) and rotate
the surface to get a feeling for what (7.11) looks like. Zooming in is also possible.Here
In the Sage code below, Newton's method is started at and iterated four times.
If is not a critical point for we can use the gradient
vector to move in a direction making strictly smaller/larger. This is
very important for optimization problems.
Let be a differentiable function, where
is an open subset. Suppose that and
for . Then
for small.
By the differentiability of ,
where is a function satisfying
for . For
with we have
When tends to zero from the right, it follows that for small .
Lemma 7.19 looks innocent, but it is the bread and butter in the
training of neural networks. In mathematical terms, training means
minimizing a function. In machine learning terms, above
is called the learning rate. One iteration (why do I choose ?)
of Lemma 7.19 is the central ingredient in an epoch
in training a neural network.
Let us briefly pause and see Lemma 7.19 in action. Consider the function
given by
and with
.
In this case and
. Therefore we may find a small , such that .
How do we choose optimally? If is too big we fail and land up in a worse point than .
Here
This is a quadratic polynomial, which is minimal for
. Therefor the minimal value reached in the direction of is .
The process now continues replacing by .
The result below is the multi variable generalization of looking for
local extrema by putting in the one variable case.
Let be a differentiable function, where
is an open subset. If is a local
extremum, then is a critical point for .
Suppose that . If is a local minimum,
then we may use in
Lemma 7.19 to deduce that for small. This contradicts the local minimality
of . If is a local maximum we can apply
Lemma 7.19 with and
to reach a similar contradiction. Therefore and
is a critical point for~.
Compute the critical points of
Is a local maximum or a local minimum for ?Hint
Look at
and and (along with Theorem 6.43).
We will prove later that a differentiable function is
strictly convex if the socalled Hessian matrix given by
is positive definite for every . This is a multivariable generalization of
the fact that is strictly convex if for every
.Now let
3D graph
You can left click the surface computed below after it has rendered and rotate
or zoom in.
- Show that is strictly convex.
-
Compute the critical point(s) of .HintThis is a numerical computation! Modify the relevant Sage window for Newton's method in the previous chapter to do it.
- For a differentiable convex function we have in general that for every . This is a multivariable generalization of Theorem 6.53.Explain how one can use (7.13) to find a global minimum for the function in (7.12). Is this minimum unique? Is for every ?
7.6 The chain rule
Recall the chain rule for functions of one variable. Here we have functions and , such that for . If is differentiable at and is differentiable at , the chain rule says that is differentiable at with This rule generalizes verbatim to functions of several variables: for compatible multivariate functions and when you replace usual multiplication by matrix multiplication.
Let and with
, open subsets and
. If is differentiable at and is
differentiable at , then is differentiable
at with
Consider given by
and
given by
We wish to use the chain rule to compute . Now,
is a matrix and is a matrix
and the chain rule reads
Of course, this agrees with the computation
But, often you cannot hope to be able to compute the function and then find
the derivative. Here the chain rule may come in handy (as in backpropagation in
training neural networks).
7.6.1 Computational graphs and the chain rule
Consider a composition of the functions and . This gives a composite function The chain rule then says that for a vector and . Notice that this is a matrix product between a matrix and an matrix.Let us write it out. Suppose that and Then for .This is simply writing out the matrix multiplication
Consider three innocent functions given by
where .
Then the composite is also a function . Let us turn things upside down. If we fix and let
vary, then may be viewed
as a function . Here and
where
It is often complicated to apply the chain rule if the
function is composed of many
functions. To organize the computation of one
works with the socalled computational graph of .A computational graph is made up of several nodes and directed edges.We will consider the example
from Example 7.9. Even though superficially looks rather simple,
it is composed of several smaller functions as displayed in the computational graph Every node in the above graph, except the input nodes (with no ingoing arrows),
represents some function . For example the node
represents a function and represents
a function .To emphasize that the non-input nodes really are functions we replace them by letters:
Every node in the above graph, except the input nodes (with no ingoing arrows),
represents some function . For example the node
represents a function and represents
a function .To emphasize that the non-input nodes really are functions we replace them by letters: Here we see that
where
The gradient is then available from the decorated graph below
Here we see that
where
The gradient is then available from the decorated graph below by multiplying the decorations on each path from the top to the input variable and the summing up. For example,
Computational graphs and the chain rule are important components in machine learning libraries. Below is an example of
the computation of in the computational graph above using the pytorch library.
by multiplying the decorations on each path from the top to the input variable and the summing up. For example,
Computational graphs and the chain rule are important components in machine learning libraries. Below is an example of
the computation of in the computational graph above using the pytorch library.
Construct a computational graph for
and detail the computation of the gradient in this context.Compute the
gradient of at using pytorch.
Consider and
given by
Compute using the chain rule and check the result
with an explicit computation of the derivative of .
We wish to show that the function given by
is convex. This means that we need to prove that
for every and every with .
This can be accomplished from the one variable case in the following way. Define
and show that is convex by using the chain rule to show that . Show
how the convexity of follows from this by using that
7.7 Logistic regression
The beauty of the sigmoid function is that it takes any value and turns it into a probability by i.e., and .Graph of the sigmoid function
Prove that
and
We will not go into all the details (some of which can be traced
to your course in introductory probability and statistics), but
suppose that we have an outcome , which may or may not happen.We have an idea, that the probability of is
dependent on certain parameters and
observations that fit into the sigmoid function as
An example of this could be where denote the
gray scale of each pixel in a image. The event
is whether the image contains the digit :
7.7.1 Estimating the parameters
Suppose also that we have a table of observations (data set)where each row has observations along with a binary variable , which is if was observed to occur and if not.Assuming that (7.14) holds, the probability of observing the observations in (7.15) is Notice that (7.16) is a function of the parameters for fixed observations .We wish to choose the parameters so that is maximized (this is called maximum likelihood estimation). So we are in fact here, dealing with an optimization problem, which is usually solved by gradient descent (for ) or solving the equations Instead of maximizing one usually maximizes the logarithm Notice that we have used Exercise 7.31 and the logarithm rules and in the computation above.
Suppose that the event is assumed to be dependent on only one observation i.e., above.
For example, could be the event of not showing up on a Monday paired with the amount of sleep
in the weekend.Here
and
Explain how the end result of the computation of in Example 7.32 is obtained and
compute .
I remember exactly where I was when first hearing about
the ChallengerSee byuistats.github.io for more details on this example disaster in 1986. This dreadful event was caused by failure of a socalled O-ring. The
O-rings had been tested before the launch for failure (=1 below) at different
temperatures (in F) resulting in the (partial) table below.
At the morning of the launch the outside temperature was
(uncharacteristically low for Florida) degrees Fahrenheit. We
wish to use logistic regression to compute the probability that the
O-ring fails.Below we have sketched how the logistic regression is carried out using the python library SciKit-Learn.
The option solver='lbfgs' chooses an algorithm for maximizing .Press the
Compute button and see the probability of failure during the launch.
In the button below is a naive implementation of gradient descent (in fact gradient ascent, because we are dealing
with a maximization problem) for the Challenger data set and logistic regression. The implementation
is derived from the introduction to gradient descent in this chapter, where we adjusted the step
with successive negative powers of .Run experiments with different initial values and number of iterations. Compare with the official
output from scikit-learn in the example above. What is going on?Also try adjusting the scikit-learn output in the example
above by removing C=25 first and then solver='lbfgs'. What happens? Compare the quality of the
solutions in terms of the gradient (which is available in the output from the Naive code).Do some internet surfing and find out in general terms what C=25 and solver='lbfgs' mean.Naive code
7.8 3Blue1Brown
Sit back and enjoy the masterful presentations of neural networks (and the chain rule) by the YouTuber 3Blue1Brown.7.8.1 Introduction to neural networks
7.8.2 Gradient descent
7.8.3 Backpropagation and training
7.8.4 The chain rule in action
Watch the video above before solving this exercise.Consider the simple neural network where
and is the sigmoid function. This neural network has input
and output . Let be a function of the output . For fixed
, we consider as a function of via
Backpropagation for training neural networks is using the
chain rule for computing the gradient
Explain how this is
done using the chain rule. Why is the method called backpropagation?Hint
where
and is the sigmoid function. This neural network has input
and output . Let be a function of the output . For fixed
, we consider as a function of via
Backpropagation for training neural networks is using the
chain rule for computing the gradient
Explain how this is
done using the chain rule. Why is the method called backpropagation?Hint
and
7.9 Lagrange multipliers
The method of Lagrange multipliers is a super classical way of solving optimization problems with non-linear (equality) constraints. We will only consider the special casewhere both and are differentiable functions.There is a very useful trick for attacking (7.17). One introduces an extra variable (a Lagrange multiplier) and the Lagrangian function given by The main result is the following.
Suppose that is a local maximum/minimum for (7.17). Then there exists
, such that is a critical point for .
Consider the minimization problem
First of all, why does this problem have a solution at all? We write
the non-linear equations
up coming from the critical points of the Langrange function. Now we know that
these can be solved and that amongst our solutions there is a minimum!
Computing the distance from the line to the point gives rise to the
minimization problem
Solve this minimization problem using Theorem 7.37.
Use Theorem 7.37 to
maximize subject to . Hint
Here you end up with the system
of linear equations in and , where you
regard as a constant. Use Gaussian
elimination to solve this system in order to
derive a (nice) quadratic equation in coming from
where you assume that . Handle the case separately.
Consider the subset
. Why is a closed subset?
Why is bounded? Hint
To prove that is bounded you can keep fixed in
and solve for . A last resort is using the plot in Sage in the Hint button below, but that
does not give any real insight unless you explain how Sage makes the plot from
the equation (7.20).
How does this relate to Theorem 5.77?Does the optimization
problem have a geometric interpretation?Hint
A rectangular box has side lengths , and . What is its
maximal volume when we assume that lies on the plane
for .
A company is planning to produce a box with volume
. For design reasons it needs different
materials for the sides, top and bottom. The cost of the materials
per square meter is dollar for the sides, dollars for the
bottom and the top. Find the measurements of the box minimizing the
production costs.Hint
Let and be the measurements. Use to
rewrite the Lagrange equations so that and are expressed in terms
of .
The sum
is called the (Shannon) entropy of the discrete probability distribution . One may use
Jensen's inequality
applied to the convex function to prove that
7.10 The interior and the boundary of a subset
Suppose that is a closed subset and is a continuous function. Recall (see Theorem 5.77) that the optimization problem always has a solution if in addition to being closed is also bounded. To solve such an optimization problem, it often pays to decompose as where is the boundary of and the interior of . The strategy is then to look for an optimal solution both in and and then compare these. In some sense we are making a "recursive" call to a lower dimensional optimization problem for the boundary . This is illustrated by the basic example: and . Here and . Notice that is finite here.The boundary of is the set of points in , which are limits of both convergent sequences with elements not in and convergent sequences with elements in . Informally these are points in , that can be approximated (arbitrarily well) both from outside and from inside .
What are the boundary points of ?
The interior of is the set of points in , which are
not limits of convergent sequences with elements not in . Informally these are points in ,
that cannot be approximated (arbitrarily well) from outside .
Compute the boundary and the interior of the subset .What is the interior and the boundary of the subset ? Same question for
.
If is an element of , then there exists an open subset
, such that . Therefore the following proposition holds, when you take Proposition 7.21 into account.
Consider an optimization problem
where is a subset, a
differentiable function and an optimal solution to (7.21). If , then is a critical point of .
Consider the minimization problem
from Example 7.38. Let us modify it to
where
We are now minimizing not only over the unit circle, but
the whole unit disk. Here
Proposition 7.46 guides us first to look for
optimal points in . Here we use Proposition 7.21 to
show that there can be no optimal points in , because
the gradient of the function is
Therefore the boundary needs to be analyzed and the usual technique
(as was implicit in Lagrange multipliers) is to find
a parametrization for the points satisfying
. There are two of those (one for the upper unit circle and one for the lower unit circle):
where .
This means that the optimization problem for the boundary turns into the two
simpler optimization problems of minimizing
subject to . These can as one variable optimization problems be solved the usual way.
The
exercises below are taken from the Calculus course.
Solve the two optimization problems
where . But first give a
reason as to why they both are solvable.Hint
First find and . Then try with Proposition 7.46
supposing that a maximal point really is to be found in and not
on .
Solve the two optimization problems
where . But first give a
reason as to why they both are solvable.
Solve the two optimization problems
where is the triangle with vertices in and . But first give a
reason as to why they both are solvable.
Use Proposition 7.46 to give all the minute details in applying
Theorem 7.37 to solve Exercise 7.42.
First rewrite to the problem, where you minimize subject to by using .
Then explain why this problem may be solved by restricting with upper and lower bounds on and . The minimum () is attained in a critical point and not on the
boundary. For one may optimize over the compact subsetand analyze what happens when .